Come misurare il tempo di esecuzione di un programma
Pubblicato il – 10 minuti di lettura – 2043 parole

Misurare le prestazioni di un programma significa tenere traccia del consumo delle risorse utilizzate dal programma. Oltre alla semplice prestazione tecnica, osservando da vicino RAM, CPU, è utile monitorare il tempo di esecuzione di un un certo task. Attività come l’ordinamento crescente di una serie di valori possono richiedere molto tempo a seconda dell’algoritmo utilizzato.
Prima di addentrarci nell’ottimizzazione di un algoritmo, è utile sapere come poter misurare il tempo di esecuzione di un programma. In questo articolo, andrò a introdurre in primis il concetto di tempo e poi ci soffermeremo su alcune tecniche per principianti per effettuare misurazioni semplicistiche (dell’ordine di microsecondo).
Misurare il tempo
Misurare il tempo di esecuzione di un programma compilato o run-time è più difficile di quanto si possa pensare, poiché molti metodi spesso non sono trasferibili su altre piattaforme. La scelta del metodo giusto dipenderà in gran parte dal sistema operativo, dalla versione del compilatore e anche da cosa si intende per “tempo”.
Wall Time vs CPU Time
Innanzitutto, è importante definire e differenziare i due termini Wall Time e CPU Time che vengono spesso utilizzati durante la misurazione del tempo di esecuzione.
Il Wall time (noto anche come ora dell’orologio) è semplicemente il tempo totale trascorso durante la misurazione. È il tempo che puoi misurare con un cronometro, supponendo che tu sia in grado di avviarlo e fermarlo esattamente nei punti di esecuzione che desideri.
La CPU Time, d’altra parte, si riferisce al tempo in cui la CPU era impegnata nell’elaborazione delle istruzioni del programma. Il tempo trascorso in attesa del completamento di altre cose (come le operazioni di I/O) non è incluso nel tempo della CPU.
Wall e CPU time
La maggior parte delle volte il tempo di sistema è preferibile al tempo della CPU, specialmente nel contesto del software parallelo. Se alcuni thread sono già terminati e non consumano più il tempo della CPU, il tempo di sistema fornisce una misura più naturale del tempo impiegato dal calcolo.
Per ottenere buoni risultati con l’ora di sistema, avrai bisogno di un computer che esegue principalmente solo il tuo software che desideri confrontare. Potrebbe essere ancora in esecuzione un sistema operativo e alcune attività in background, ma nessuna interfaccia grafica o qualsiasi altro software applicativo. Questo ti darà il miglior ambiente di test possibile e quindi l’utilizzo dell’ora di sistema è la scelta giusta.
Tecniche
Nelle sezioni seguenti andremo a vedere le tecniche più usate per quantificare l’ottimizzazione in termini di tempo.
Il ragazzo intelligente: cronometro
Il più semplice metodo ed intuitivo per misurare il tempo è utilizzare un cronometro manualmente nel momento in cui si mette in esecuzione il programma. Supponendo che riusciate nello stesso istante a far partire il cronometro e il programma, l’opzione richiede che il programma stampi un certo avviso alla fine dell’esecuzione (o alla fine di un sottoprogramma).
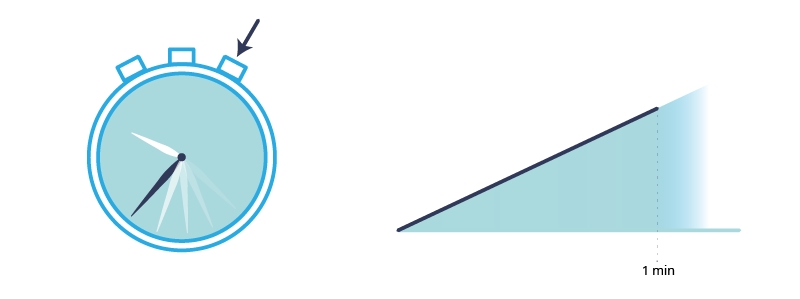
Una volta che si preme il bottone, il tempo viene incrementato.
Questa tecnica non è la migliore, dato che mediamente un umano per reagire ci mette dai 0.25 secondi fino a 1 secondo intero, per poi passare un altro buon secondo sul premere un bottone fisicamente o digitalmente. In più spesso i cronometri digitali non arrivano al grado di precisione che ci serve (dato che i computer sono molto veloci rispetto agli umani.)
Utility Time
Un’alternativa più veloce e automatizzata del cronometro manuale, è l’utility time che arriva prontamento in nostro soccorso: è molto semplice da utilizzare e non richiede particolari settaggi. È sufficiente utilizzare la seguente sintassi time ./nome-del-programma dove nome-del-programma è il nome del file o in alternativa anche il comando da eseguire.
Insieme al risultato del programma, l’utility time stampa tre tipi diversi di tempi:
- Real time – corrisponde alla misurazione del tempo reale (in termini di secondi) utilizzando l’orologio interno del sistema;
- User time – corrisponde alla misurazione del tempo in cui le istruzioni della sessione “utente” vengono eseguite;
- System time – corrisponde alla misurazione del tempo in cui le istruzioni della sessione “Supervisore” vengono eseguite (generalmente un tempo molto minore rispetto allo User time nei problemi didattici);
Non è detto che User_time + System_time = Real_time. User e System Time vengono calcolati in “CPU-seconds”, ossia secondi calcolati in base al ciclo di clock della CPU.
Il perché della differenza tra User e System intine è data da alcuni meccanismi interni su come funziona l’esecuzione di un processo. In linea generale e in maniera molto semplicistica, possiamo individuare due parti a sè stanti all’interno di un sistema operativo. Una parte utente e una parte Supervisor (modalità kernel) con privilegi superiori rispetto all’utente.
La maggior parte delle istruzioni di un processo sono eseguibili in modalità utente e non richiedono privilegi necessari. Quando invece si vuole interagire per esempio con I/O, allocare memoria od effettuare altre operazioni che potrebbero interferire con il comportamento di altri programmi, è necessario effettuare delle chiamate di sistema al Supervisore che provvederà ad eseguire il comando.
Questo è anche chiamato Principio di Privilegio minimo ed è molto importante: in questo modo, l’utente non ha i privilegi massimi e non è libero di fare ciò che vuole. In caso di system call “illegali”, il supervisore si limiterà a terminare il processo senza fornire informazioni aggiuntive.
time integrato che fornisce informazioni simili sull’uso del tempo e eventualmente altre risorse. Per accedere all’utility in sè, potreste bisogno di specificare il suo percorso (/usr/bin/time).
Per determinare se time è un binario o una keyword riservata all’interno, è utile eseguire type time.Contare il clock
Per eseguire correttamente un programma, è fondamentali che tutte le sottoparti siano sincronizzate al tempo giusto. Dal punto di vista fisico, un elaboratore è composto da segnali elettrici e se ritardano oppure si sovrappongono, il sistema potrebbe non rispondere correttamente.
Il direttore d’orchestra che si occupa di sincronizzare tutte le parti è un segnale “universale” a 1 chiamato CLOCK. È generato da un minerale (spesso quarzo) all’interno della CPU e la frequenza del segnale (ovvero quando passa da 0 a 1) è determinata dalla frequenza della CPU. Ad esempio con una CPU 1 GHz, si parla di 10^9 volte che il segnale di clock passa da 0 a 1 in un secondo, quindi ci mette circa 10^-9 secondi per passare da 0 a 1.
I componenti interni dell’elaboratore sono costruiti in modo tale da essere “sollecitati” solo nel momento in cui il segnale di clock cambia. Se i dispositivi elettronici rispondono nel fronte di salita, cioè quando il clock passa da 0 a 1, si parla di rising-edge, viceversa falling-edge, ovvero quando si passa da 1 a 0.
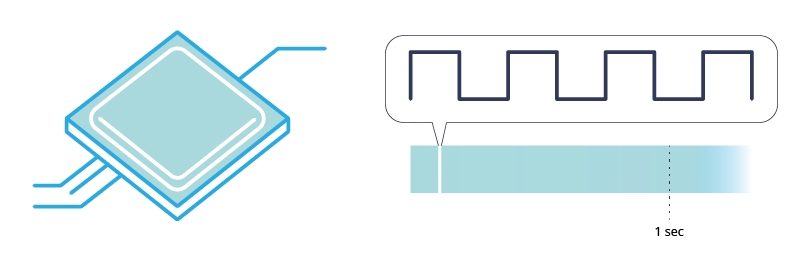
La CPU ha un segnale di clock interno che va da 0 a 1 in microsecondi.
Fatta questa premessa, è intuitivo pensare che se si ha la quantità di cicli di clock effettuati in un secondo e so la differenza di cicli di clock calcolati tra due istanti, posso convertirlo in secondi.
Questo è il risultato della funzione clock();, infatti per misurare il tempo d’esecuzione, è possibile effettuare in due istanti di tempo diverso una misurazione sui cicli di clock passati da un certo inizio, come avviene per l’utility time. A quel punto, trovando la differenza e conoscendo i CLOCKS_PER_SEC posso calcolarmi i secondi passati dalla prima chiamata di clock(); alla seconda chiamata.
clock_t start = clock();
// facciamo delle operazioni
clock_t end = clock();
long double seconds = (float)(end - start) / CLOCKS_PER_SEC;
Il tempo della CPU è rappresentato dal tipo di dati clock_t, che è un numero di tick del segnale di clock. Dividendo il numero di cicli di clock per i clock per secondi, si ha la quantità totale di tempo in cui un processo ha utilizzato attivamente una CPU dopo un evento arbitrario. Notiamo che CLOCKS_PER_SEC è già definito dal compilatore ed è necessario includere la libreria time.h.
CLOCKS_PER_SEC non è preciso al millesimo di secondo (di default il valore di quella variabile è 1000000), quindi si potrebbe avere una differenza sostanziale tra il valore misurato con clock() e l’utility time.Funzione time() e il tempo epoch
In questo caso introduciamo un terzo concetto: il tempo “epoch”. Un’epoca è una data e un’ora a partire dalla quale un computer misura l’ora del sistema. La maggior parte dei sistemi informatici determina l’ora come un numero che rappresenta i secondi rimossi da una particolare data e ora arbitraria.
Ad esempio, Unix e POSIX misurano il tempo come il numero di secondi trascorsi dal 1° gennaio 1970 alle 00:00:00 UT, un punto nel tempo noto come “epoca Unix”. L’epoca dell’ora NT su Windows NT e versioni successive si riferisce all’ora di sistema di Windows NT in intervalli di (10 ^ -7) s da 0 1 gennaio 1601. È possibile immaginare l’epoch time come l’anno 0 del calendario gregoriano.
Potresti chiederti, cosa succede se devo rappresentare una data prima dell’epoch time? Nessun problema, ci sarà solo un valore negativo. Quindi se mai dovresti ottenere un valore negativo, no il tuo computer non ha problemi e no, non devi cambiare la batteria dell’orologio interno.
La funzione time() implementata in time.h restituisce il valore del tempo in secondi da 0 ore, 0 minuti, 0 secondi, 1 gennaio 1970, nel fuso orario di Greenwhich (UTC +0). Se si verifica un errore, restituisce -1.
Il time_t di dati Unix che rappresenta un punto nel tempo ed è, su molte piattaforme, un intero con segno , tradizionalmente di 32 bit (ma si è esteso a 64 bit), che codifica direttamente il numero di tempo Unix come descritto nella sezione precedente. Essere a 32 bit significa che copre un intervallo di circa 136 anni in totale. Se si estende il dato a 64 bit, si copre un intervallo di + e - 293 miliardi di anni!
time_t begin = time(NULL);
// Chiamata ad una funzione che occupa tempo
time_t end = time(NULL);
printf("Sono passati %d secondi dal punto begin ad end", (end-begin));
Dato che in questo caso abbiamo il tempo in secondi, questo metodo è spesso approssimativo se si vuole misurare con una precisione inferiore al millesimo di secondo.
Metodi più avanzati
In questo articolo, ho descritto svariate tecniche per implementare una sorta di cronometro interno al programma utilizzando le librerie built-in di C. Le API di C però sono limitate e per lo più sono ad uso didattico. Su un progetto a grosse dimensioni, è necessario non solo saper misurare, ma osservare in tempo reale ciò che succede a livello di prestazioni.
Perché quando tento di accedere alla risorsa X, c’è un picco nella CPU? Come individuo i colli di bottiglia? Per poter rispondere a queste domande, esiste un applicazione a sè stante chiamata “Profiler” che è molto utile nel tracciare le prestazioni di un programma.
I profiler possono analizzare fino a ogni singola riga di codice. L’utilizzo di un profiler non sempre sembra ben apprezzato dagli sviluppatori dato che rallenta in modo quasi esponenziale il programma. Mentre la maggior parte considera i profiler uno strumento situazionale non pensato per l’uso quotidiano, la profilazione del codice può essere un vero toccasana quando ne hai bisogno.
I profiler sono ottimi per trovare il percorso attivo nel codice. Capire cosa sta utilizzando il venti percento dell’utilizzo totale della CPU del codice e quindi determinare come migliorarlo sarebbe un ottimo esempio di quando utilizzare un profiler del codice. Inoltre, i profiler sono ottimi anche per individuare tempestivamente le perdite di memoria, nonché per comprendere le prestazioni delle chiamate.
Conclusione
“Se puoi migliorare qualcosa dell’uno percento ogni giorno, nel corso di un mese migliorerai del trenta percento”. Ciò che fa davvero la differenza è il miglioramento continuo nel tempo.
Cosa significa? Dedicare risorse al monitoraggio del programma è utile perché anche solo un piccolo miglioramento può fare la differenza. Innumerevoli sono gli esempi online del perché si dovrebbe adottare la strategia di misurare, investigare e risolvere. How I cut GTA Online loading times by 70%, 0(n^2) in CreateProcess e Don’t Copy That Surface sono tra i miei articoli preferiti perché mostrano chiaramente come funziona il processo e i relativi effetti.
Nei prossimi articoli, cercherò di presentare un caso studio di un ottimizzazione di un algoritmo e scriverò anche di alcuni famosi profiler (tra tutti, gprof). Come sempre, non esistate a contattarmi su Twitter o via email.