Phishing: persuadere attraverso una voce sintetizzata da AI - Parte 1
Pubblicato il – 8 minuti di lettura – 1673 parole

Mi arrivano dalle 10 alle 20 email al giorno e più della metà sono tentativi di spear phishing, ovvero una tipologia di truffa telematica via mail che il più delle volte mira ad ottenere dati personali della vittima, inclusi anche username e password di eventuali account mail, attraverso pagine forgiate ad hoc per simulare le sezioni di login dei servizi più conosciuti (google mail, hotmail, mail.ru ma anche Twitter, Amazon).
“Il tuo account è stato bloccato per verifiche di sicurezza..”, “il pacco sta per essere recapitato ma..”, “il tuo dominio è scaduto”: sono solo alcuni esempi dei contenuti/messaggi che l’utente riceve al fine di cattuarne l’attenzione e spingerlo a cliccare sul link “civetta” che, spesso, viene camuffato in modo tale da apparire lecito. Vi sono varie tecniche che consentono agli attaccanti la buona riuscita: messaggio della email senza errori grammaticali, domini che sembrano uguali agli originali ma differiscono di una o più lettere (fai un esempio qui).
La mia analisi si è focalizzata su un approccio più spinto e più mirato alla psicologia: è possibile persuadere una persona ad immettere i propri dati personali attraverso una voce generata da un’intelligenza artificiale?
Social engineering e phishing
Social engineering is using manipulation, influence and deception to get a person, a trusted insider within an organization, to comply with a request, and the request is usually to release information or to perform some sort of action item that benefits that attacker. ~ Kevin Mitnick
L’ingegneria sociale viene definita “l’arte” di ottenere in maniera subdola informazioni che non dovrebbero essere divulgate. Esistono vari metodi per ricavare i dati di interesse, tra cui il phishing, ma anche pretexting, baiting e attacchi quid pro quo. L’obiettivo finale del malitenzionato è ottenere credenziali oppure provocare un’azione che sia vantaggiosa per l’attacco.
In questo articolo, mi focalizzerò sullo spear phishing che è un attacco mirato per cercare di ricavare ogni informazione sensibile sfruttando l’ingenuità dell’utente a cui è diretto. Inizialmente, si utilizza l’email spoofing come “esca” per attirare l’attenzione e portare l’utente ad immettere le proprie credenziali su una pagina creata dall’attaccante.
Il fenomeno dello spear phishing è iniziato a metà degli anni ‘90 quando un ragazzino di diciassette anni conosciuto con il nome “Da Chronic” rilasciò lo strumento “AOHell” che permetteva di generare pagine false per ottenere password e carte di credito da utenti del social network AOL. Da quel momento, il numero di messaggi e email contenti phishing è aumentato esponenzialmente e le tecniche si sono sempre più affinate. Ad oggi si contano più di 200 milioni di attacchi tentati, non contando le centinaia di migliaia di email di spam che ogni anno vanno a finire chissà dove. L’argomento risulta molto attuale: nel periodo del COVID-19, la APWG (Anti-Phishing Working Group) ha notato un incremento negli attacchi soprattutto contro strutture sanitarie e infrastrutture statali.
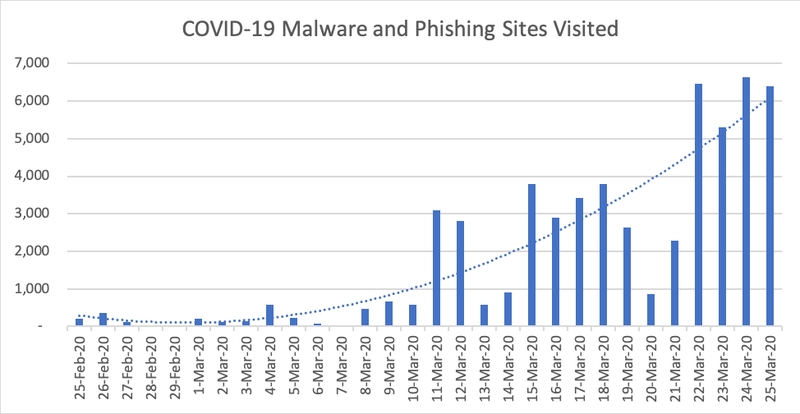
Seguente grafico preso da Menlo Security
Psicologia: tecniche della persuasione e prosodia
Esistono varie tecniche per persuadere e cercare di ottenere le credenziali dall’utente. In primis, si sfrutta il fatto di clonare la pagina di interesse: una persona per distrazione o per superficialità potrebbe non controllare l’autenticità della pagina, immettendo senza pensare i propri dati.
Si può portare la complessità di un attacco phishing ad un altro livello? Molto spesso, sono solo pagine di login ma se fossero più elaborate? Mi sono interessato in particolare di una tecnica: la persuasione tramite la voce. Diverse ricerche scientifiche mostrano come una persona sia più predisposta a fare qualche azione se comandata da una voce umana. È possibile tuttavia avere lo stesso risultato con una voce “sintetizzata da un AI”? E se si applicasse lo stesso a una pagina di login?
Attualmente, si sa poco o nulla su quanto effettivamente una voce sintetizzata artificialmente sia più convincente di una voce umana.
A cross-study exploratory analysis and replication experiment reveal that communicators tend to speak louder and vary their volume during paralinguistic persuasion attempts, both of which signal confidence and, in turn, facilitate persuasion. “How the Voice persuades”
Il linguaggio sintetizzato artificialmente non ha tutte le caratteristiche della voce umana per esprimere e trasmettere emozioni. Tuttavia, l’API Web Speech ha alcuni elementi modificabili di prosodia. La prosodia include tutti gli aspetti “secondari” del linguaggio come il tono della voce (pitch), la lunghezza dei suoni (speed), il volume (volume) e la qualità del suono. La prosodia fornisce molte informazioni aggiuntive sull’atteggiamento e sul significato di una frase. Porgere un saluto, chiedere un’informazione a seconda del tono può dare risultati differenti. Immaginiamo una persona che chieda un piacere: a seconda del modo in cui pone la richiesta può derivare un risultato diverso.
Web Speech API: Speech Synthesis
Nel 2012, un gruppo della community di W3C si riunisce e sviluppa un nuovo standard chiamato [“Web Speech API”] per fornire agli sviluppatori un’interfaccia per “speech-to-text” e “text-to-speech”. Consente all’applicazione sia di capire il testo da un discorso pronunciato dall’utente, sia di trasformare un testo in un discorso parlato attraverso una voce sintetizzata da un intelligenza artificiale. Già a partire da Chrome 33, un API sperimentale era stata rilasciata per poi essere ufficialmente introdotta a partire dal 2014.
Utilizzeremo l’oggetto SpeechSynthesisUtterance che rappresenta una richiesta vocale.

rate: imposta la velocità, accetta valori tra [0 e 10]pitch: imposta il tono, accetta valori tra [0 - 2]volume: imposta il volume, accetta valori tra [0 - 1]lang: imposta la lingua (tag di lingua BCP 47, come en-US o it-IT)text: imposta il testo, può contenere al massimo 32767 caratterivoice: imposta la voce tra le 52 disponibili (per ottenerle, si utilizzawindow.speechSynthesis.getVoices();)
var msg = new SpeechSynthesisUtterance();
var voices = window.speechSynthesis.getVoices();
msg.voice = voices[0];
msg.lang = 'it-IT';
msg.pitch = 1.0;
msg.text = 'Mi piace la pizza';
speechSynthesis.speak(msg);
Per eseguire la richiesta, si deve chiamare la funzione “speak” del metodo “speechSynthesis”: speechSynthesis.speak(obj). Come specificato nel codice sorgente di Chromium, gli attributi volume, rate, pitch accettano valori float. Le modifiche di valori come volume durante una richiesta vocale saranno applicati alla successiva chiamata di speechSynthesis.speak(obj).
Accorgimenti
Non tutte le voci sono già presenti sul browser: alcune infatti sono disponibili solamente online; se non specificato, la voce utilizzerà l’accento della lingua impostata nel browser. È inoltre possibile modificare il parametro voice.localService per impostare se la voce sintetizzata è fornita o meno online (per risparmiare banda ndr). Ricordo che la lingua sfalsata rispetto alla lingua sintetizzata dall’AI può generare sospetti (red flags) non solo perché ha un accento diverso, ma anche i numeri e le percentuali sono letti secondo la lingua dell’AI. Per esempio, se si utilizza una voce preimpostata per it-IT con lang en-US, la seguente stringa 2% sarà due-percento e non two percent.
Quando l’API è stata implementata nel 2014 con Chrome, si è assistiti ad un fenomeno crescente di abuso delle API nelle pubblicità sui dispositivi mobile e desktop. Per questo, Chrome al momento richiede una iterazione (un tocco) da parte dell’utente per poter effettuare la richiesta all’API; tuttavia Safari e Firefox non impongono questo limite. Un banale modale per “Accetta Cookie” potrebbe funzionare.
Più la campagna di phishing è mirata, più avrà successo. Per questo, si è preferito utilizzare il nome dell’utente per richiamarlo diverse volte: se infatti la scheda diventava inattiva, il browser tenta di chiamare l’utente.
// Dato che la scheda può essere "attiva" o "chiusa", aumento la variabile close di 1 ogni volta che c'è l'evento visibility change. Quando il contatore è pari, allora la scheda è chiusa, quindi chiamo l'utente.
var close = 0;
document.addEventListener('visibilitychange', function(){
close++;
if(close % 2) remind_user();
});
Per evitare codice ridondante, si crea una funzione speak() che richiama l’API SpeechSynthesis.
function speak(message, speed, pitch){
var speech = new SpeechSynthesisUtterance();
var voices = window.speechSynthesis.getVoices();
// La voce è abbinata alla lingua
speech.voice = voices[8];
// Supponiamo di avere sempre lo stesso utente
speech.lang = 'en-US';
speech.rate = speed;
speech.pitch = pitch;
speech.text = message;
}
In questo modo, possiamo scrivere:
var messaggio = 'Ciao Mondo!';
speak(messaggio);
Un esercizio lasciato al lettore è quello di sviluppare attraverso backend una pagina personalizzata dato il solo nome dell’utente da targetizzare (la lingua è spesso data sullo User-Agent anche se talvolta può ingannare).
Inoltre, per non accavallare le richieste, utilizziamo gli eventi onspeak in concomitanza con i click effettuati dall’utente. Infatti, si mettono in pausa tutte le voci nel caso in cui l’utente inizia a scrivere le proprie credenziali (l’elemento input cambia stato in focus).
Uno dei punti chiavi è il contenuto della voce. Ho optato per un approccio più “diretto” e categorico utilizzando elementi verbali imperativi. Invece di una frase cordiale, come “si prega di [verbo]”, si è scelto di utilizzare in modo mirato “[verbo]” per indurre subito l’azione come se fosse una “Call To Action”. Esempio: “Scrivi la tuo username e password per continuare”.
Ipotesi
Non ho trovato molte ricerche riguardo questo argomento: poco ancora si sa effettivamente su un possibile collegamento tra elementi di prosodia e azione che ne consegue. L’articolo potrebbe essere un buono spunto per condurre una ricerca scientifica più “accademica”.
Seppur limitatamente, proviamo ad ipotizzare alcuni scenari di fronte al quale l’utente può trovarsi. Come abbiamo potuto osservare, la persuasione a voce costituisce solo un elemento aggiuntivo alla campagna di phishing: gli elementi grafici e l’email costruita ad-hoc devono esserci per poter avere una campagna phishing più efficace.
Dato che il Web Speech non è largamente usato, men che meno su pagine di login, la voce in molti casi potrebbe essere un campanello d’allarme per la maggior parte degli utenti. In questo caso, si ipotizza che l’utente scopra del tentativo di phishing abbandonando la pagina.
Un caso più interessante riguarda l’utilizzo degli assistenti vocali. Se si implementasse una pagina web che riproducesse un assistente vocale, le persone si aspetterebbero una voce. L’elemento della voce non gioca più come “fattore sorpresa”; inoltre la voce robotica dell’AI implementata sui principali browser Chromium-based è molto simile alla voce dell’assistente vocale di Google.
Se vuoi partecipare alla ricerca in modo da poter confermare o meno un ipotesi, ti lascio la mia email per scrivermi! Presto potrei inviarti una email di phishing per studiare il comportamento degli utenti.

