Tecniche per Impostare le Periferiche via DMA e PIO
Pubblicato il – 14 minuti di lettura – 2858 parole
Nella parte quinta dell’indagine abbiamo concentrato i nostri sforzi nel comprendere come fosse strutturato il firmware. Abbiamo analizzato la cartella con gli eseguibili di sistema e abbiamo approfondito i vari file di configurazione.
Prima di affrontare l’analisi di un device driver dobbiamo concentrarci su alcuni aspetti hardware che ci faranno comodo per il prossimo articolo. Questi aspetti includono la gestione delle periferiche e dei dispositivi di input/output.
I Registri Associati alle Periferiche
Mouse, tastiera, webcam e sensori ottici hanno qualcosa in comune: sono tutte delle periferiche, dispositivi hardware che estendono le funzionalità di un computer e che si interfacciano con il mondo reale. Esistono periferiche di input (mouse, tastiera, sensori in genere), di output (tastiera) ma anche di input/output (la scheda di rete).
Le periferiche sono sempre stati difficili da gestire per via delle innumerevoli configurazioni diverse tra produttori. Come possiamo far dialogare tra sistema operativo e periferica? Ad ogni periferica sono associati dei registri e un controllore hardware che permettono di impartire comandi di basso livello alla periferica. Un controllore hardware è un’interfaccia elettronica che permette di comandare un dispositivo (spostare un’inquadratura, configurare la modalità del dispositivo), mentre un registro è una memoria volatile molto costosa, ma anche molto veloce che permette lo scambio praticamente istantaneo delle informazioni.
Ogni dispositivo/periferica è costituito da almeno tre registri:
- un registro per i dati (data register) contenente una certa informazione che il sistema operativo deve sapere - esempio: posizione del mouse, carattere della tastiera digitato;
- un registro per lo stato della periferica (status register) - ad esempio se è stata recentemente utilizzata, se è successo qualche errore improvviso;
- un registro per il controllo (control register) che permette di impartire comandi al dispositivo;
Accedendo ai dati di tali registri è possibile configurare, installare, comandare un qualsiasi dispositivo. Il problema principale è dato dalla varietà delle configurazioni hardware presenti sul mercato.
Prendiamo per esempio il concetto astratto di mouse: quanti produttori di mouse esistono al mondo? Di certo ce ne sono abbastanza da non poter costituire uno standard di comunicazione. Non è pensabile di codificare, all’interno del codice, un algoritmo che possa interfacciarsi con tutti i dispositivi del mondo. Per ovviare al problema, i produttori quindi allegano insieme al prodotto fisico un programma, chiamato device driver che consente a chi installa la periferica di poterla utilizzare.
Il device driver presenta un’interfaccia ad alto livello per il sistema operativo e i servizi applicativi che vogliono utilizzare, configurare ed impostare una periferica. Dal punto di vista tecnico, il device driver non è altro che un programma mappato in una posizione di memoria ben precisa. Ogni volta che il sistema operativo riceve una richiesta di utilizzo di tale periferica, il sistema provvede a richiamare il gestore, ovvero il device driver che provvederà a fornire il servizio richiesto.
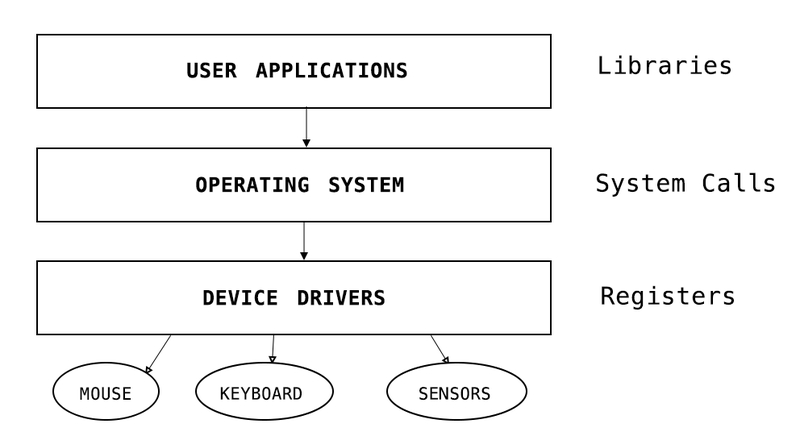
Panoramica dell'iterazione tra device drivers e sistema operativo.
Dal momento che il device driver è proprietario e considerato che esso costituisce un “collo di bottiglia” per controllare l’hardware, siamo molto interessati a comprendere come un dispositivo funzioni e che impostazioni esso possa prevedere. È possibile infatti nascondere funzionalità, impostare limiti stringenti tramite device driver: non a caso, la maggior parte dei problemi con le periferiche avviene per un problema al device driver e non al dispositivo stesso. Non sempre però il produttore allega il device driver: è possibile anche scriverlo da zero, seguendo la documentazione da parte del produttore.
Per condividere i dati di una periferica e trasmetterli all’elaboratore centrale, esistono due principali tecniche:
- Programmed Input Output: tecnica nata agli albori dell’informatica che continua ad essere utilizzata per dispositivi embedded. Scopo principale: trasferire dati tra la memoria e la periferica, utilizzando la CPU. Interferisce con il normale flusso d’esecuzione.
- Direct Memory Access: ottimizzazione della tecnica Programmed Input Output. Prevede un nuovo dispositivo che si interfaccia direttamente con la memoria e con le periferiche, ma non prevede il contributo della CPU.
Nei prossimi paragrafi, esploreremo meglio la differenza tra le due tecniche introducendo anche un protocollo di comunicazione che viene utilizzato all’interno della videocamera Reolink RLC-810A.
Programmed Input Output
La tecnica Programmed Input Output è un metodo di trasmissione dati tra un dispositivo periferico e l’unità di elaborazione centrale. Ogni trasferimento di dati viene avviato da un’istruzione nel programma che coinvolge la CPU. Il processore esegue un programma che gli fornisce il controllo diretto dell’operazione di I/O, incluso il rilevamento dello stato del dispositivo, l’invio di un comando di lettura/scrittura e il trasferimento dati.
Il funzionamento del Programmed Input Ouput può essere riassunto come segue:
- la CPU sta eseguendo un programma e incontra un’istruzione relativa ad un’operazione di I/O.
- la CPU esegue l’istruzione, interrogando il dispositivo periferico;
- la periferica esegue l’azione richiesta in base all’istruzione conferita dalla CPU e imposta i bit appropriati nel registro di stato.
- Il processore controlla periodicamente lo stato del modulo I/O fino a quando non rileva che l’operazione non è stata completata.
Come è facilmente intuibile, il passo 4 è quello che utilizza la CPU per più tempo: controllare ciclicamente lo stato dell’operazione è uno spreco di tempo inutile. Questo è il principale svantaggio della tecnica Programmed Input Output. La CPU deve fermare il flusso di esecuzione per poter controllare periodicamente lo stato della periferica, impattando sulle prestazioni del sistema.
Il secondo svantaggio del PIO sta nella dimensione dei dati da poter inviare alla CPU. Dal momento che i registri sono di dimensione fissa e di dimensione esigua, la CPU deve spendere parecchi cicli di clock per poter trasferire grandi moli di dati. Le velocità dei PIO vanno da pochi kByte al secondo fino a 55 MB per secondo, più che sufficiente per alcuni scopi embedded.
Dall’altra parte, non implementare un DMA consente di avere una logica elettronica molto più semplice. Questo impatta fortemente sui costi di sviluppo, rendendo possibile un risparmio su larga scala. La semplicità del PIO è fortemente scelta da produttori di dispositivi embedded perché i dispositivi periferici non necessitano di trasferire grosse quantità di dati ad alta velocità. Per il collegamento tra il sensore ottico Omnivision e la board, Novatek ha deciso di non implementare il DMA, sfruttando invece uno dei due core della CPU che viene interamente dedicato all’encoding dell’immagine.
Direct Memory Access
Quando si hanno più dispositivi hardware (ad esempio scheda di rete, tastiera, mouse) che trasferiscono dati in modo repentino, come in un sistema general purpose, l’utilizzo del programmed input ouput potrebbe pesare sulle prestazioni della CPU. Serve quindi pensare ad un’ulteriore ottimizzazione che possa eliminare il contributo della CPU.
Per accedere ai registri, sia il sistema operativo che i dispositivi devono condividere uno spazio comune. Utilizzare i registri generici già forniti dalla CPU inoltre è fuori discussione perché significherebbe occupare la CPU per un certo tempo, fermando l’esecuzione di processi del sistema operativo. La soluzione sta nell’adottare un dispositivo chiamato DMA (Direct Memory Access) che permette ai dispositivi di accedere alla memoria principale senza interrogare o interrompere il flusso di esecuzione della CPU.
Potrebbe non sembrare intuitivo come approccio, ma originariamente si era chiesto: dove possiamo archiviare i registri? Si è subito pensato alla memoria centrale, ovvero alla RAM, come spazio condiviso per mappare i registri. Il problema però era che la RAM poteva essere solo accessibile attraverso alla CPU. La CPU infatti era l’unico elemento hardware che permetteva di recuperare un’informazione dato un indirizzo della RAM. Implementando un nuovo metodo per recuperare i dati, tralasciando il contributo della CPU, il DMA consente di far accedere i dispositivi a propri registri senza dover interrompere il flusso d’esecuzione: un notevole risparmio di risorse e tempo!
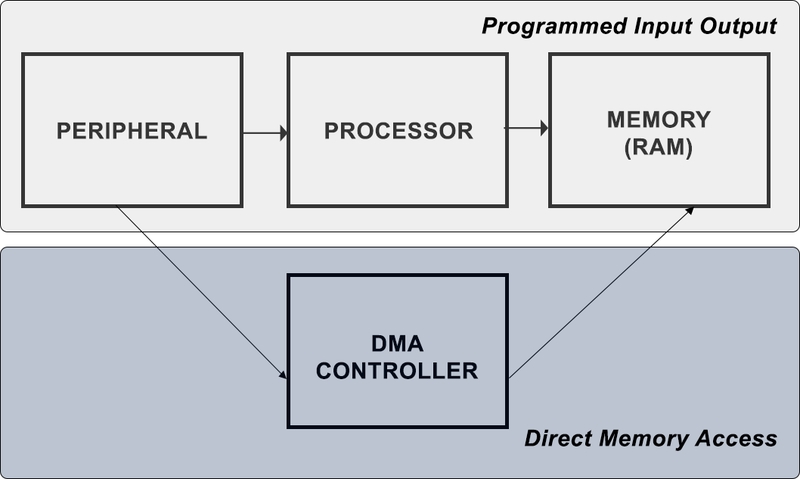
Differenza tra Programmed I/O e Direct Memory Access.
Dal momento che la memoria principale consente l’archiviazione di più registri, non c’è attualmente limite “virtuale” al numero di registri per ogni dispositivo. Ogni dispositivo ha una serie di registri che vengono mappati sulla memoria principale ad alcuni indirizzi ben precisi. Il device driver sa sia come manipolare i registri sia a che indirizzi esso sono. In questo modo, si ha una gestione della periferica molto semplificata e molto ottimizzata.
Il DMA in particolare si preoccupa di spostare dati dal bus (canale di comunicazione dove scorrono i diversi segnali) alla memoria e viceversa. Il dispositivo periferico non deve preoccuparsi di gestire i segnali al DMA, ma semplicemente di posizionarli sul bus.
Bus
Come però arrivano i segnali dalla periferica al DMA controller? Principalmente attraverso un canale di comunicazione chiamato Bus condiviso da tutte le periferiche e dall’elaboratore centrale. Il bus rappresenta il metodo mediante il quale i dati vengono comunicati tra tutte le parti interne all’elaboratore centrale.
All’interno di una board, esistono principalmente tre tipi di bus che sono simili ai tre tipi di registri menzionati in alcuni paragrafi precedenti. Questi includono: il bus dati che consente la condivisione di dati tra i dispositivi, il bus degli indirizzi che indica ai dispositivi la destinazione dei dati e il bus di controllo che coordina l’attività tra le varie periferiche per prevenire le collisioni di dati. Succede una collisione quando due dispositivi inviano segnali nello stesso momento causando la corruzione dei dati.
Quando una periferica vuole scrivere qualche dato all’interno di un proprio registro, utilizza un indirizzo fisso che consente ad un controllore di mappare quel registro all’interno della memoria. Questa azione può essere svolta sia da un DMA controller, sia dalla CPU stessa.
GPIO
Un altro dispositivo molto importante all’interno della gestione delle periferiche consiste nel GPIO, General Purpose Input Output, un’interfaccia generica hardware che consente a microcontrollori di interagire con altri dispositivi. Dal punto di vista hardware, sono una serie di PIN di utilizzo “generale”: ogni pin può essere impostato liberamente per funzionare come input o come output.
Il GPIO si rivela essenziale per portare l’alimentazione alle periferiche che lo richiedono, come in questo caso il sensore Omnivision. Gestire il GPIO e maneggiare i diversi PIN richiede grande abilità e attenzione perché se si collega un dispositivo ad un PIN sbagliato, c’è il rischio che la corrente elettrica danneggi parte del dispositivo.
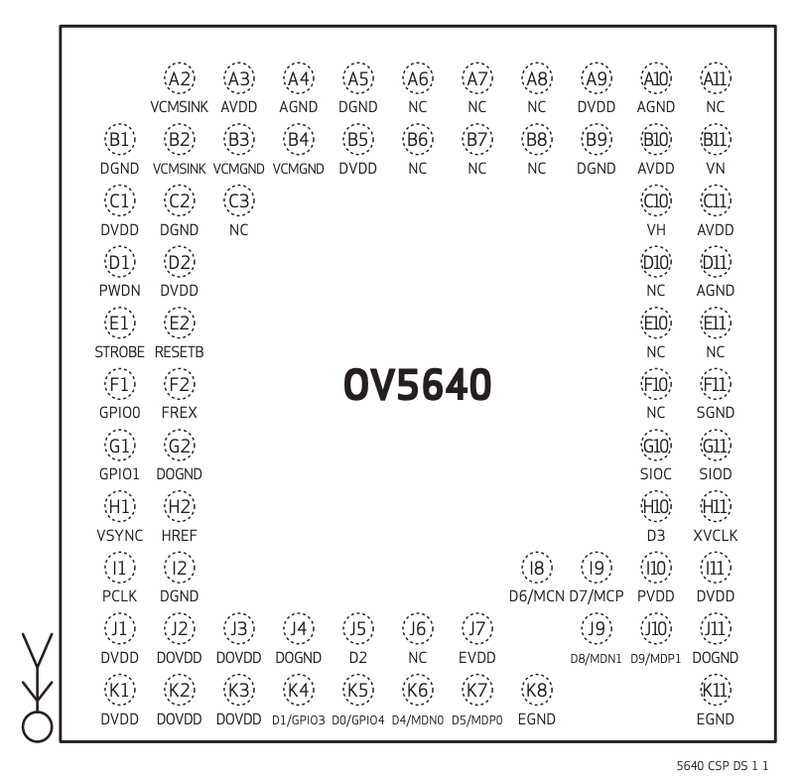
Esempio di schema dei pin per un sensore Omnivision
Il produttore allega insieme alla periferica, uno schema che consente di collegare i diversi PIN al GPIO. La CPU utilizzando i diversi PIN consente al device driver di poter cambiare stato al dispositivo periferico.
I2C
Introdotti alcuni concetti teorici, possiamo affrontare un protocollo di comunicazione del bus utilizzato nella board di Novatek: il protocollo I2C. Il protocollo I2C è un protocollo di comunicazione progettato per connettere circuiti integrati che sono sulla stessa board.
Il Bus rappresenta un cavo condiviso in cui passano diverse informazioni. Per evitare possibili problemi (collisioni tra i vari segnali), è necessario utilizzare un protocollo: un’insieme di regole che stabilisce come inviare i segnali e quando. Nota che I2C non definisce la semantica dei messaggi (come devono essere interpretati), ma solamente la tempistica.
L’arconimo I2C sta per Inter-Integrated Circuit Bus ed è stato principalmente introdotto dalla Philips per connettere i circuiti integrati all’interno delle TV degli anni ‘80, in modo da abbandonare i transistor più grandi a favore dei primi circuti integrati.
Ogni dispositivo connesso all’interno di un bus può avere due principali ruoli:
- Master: un dispositivo che si assume la responsabilità della conversazione, genera il clock e avvia la comunicazione ai dispositivi slave; solo un master può essere presente per il protocollo I2C.
- Slave: tutti gli altri dispositivi che rispondono alle richieste da parte del master, ricevono il clock dal master;
I2C ha due bus principali che connettono tutti i dispositivi periferici. In particolare: SDA (Serial DAta), bidirezionale che consente di scambiare dati serialmente, e SCL (Serial CLock), unidirezionale dal master agli slave che memorizza il clock per la trasmissione. Tensioni tipiche utilizzate sono 3,3 V oppure 5 V.
Per identificare ogni dispositivo connesso al bus, il protocollo utilizza un sistema di indirizzi a 7 bit e in aggiunta un altro bit che indica quale operazione il dispositivo master sta richiedendo (se in scrittura 0 oppure in lettura 1).
Diamo uno sguardo a ciò che accade quando un master chiede un’operazione di scrittura su una periferica:
- Master invia un segnale di START che identifica la volontà di iniziare una nuova connessione;
- Master invia l’indirizzo della periferica che vuole interrogare;
- Master invia il numero del registro che deve essere scritto;
- Master invia i dati che devono essere scritti (nota che questo punto è ripetuto per ogni registro che deve essere scritto)
- Master invia il segnale di STOP che identifica la conclusione della trasmissione;
Allo stesso modo, per un’operazione di lettura:
- Master invia un segnale di START;
- Master invia l’indirizzo del dispositivo che vuole interrogare;
- Master invia il numero del registro da leggere;
- Master invia un nuovo segnale di START;
- Master invia l’indirizzo del dispositivo;
- Slave invia i dati (questo passo viene ripetuto per ogni registro che deve essere letto)
- Master invia il segnale di STOP
Questa sequenza di segnali deve essere inviata per ogni operazione di scrittura e lettura. Il protocollo I2c ha anche il supporto per l’operazione con feedback. Per ogni byte scritto o letto, il dispositivo Slave risponde con un segnale ACK (un bit a 0), detto di acknowledge, che indica se l’operazione è avvenuta con successo.
A seconda della versione del protocollo I2C utilizzato, è possibile che si arrivi anche a qualche MB al secondo, più che sufficiente per gestire quantità di dati sui dispositivi embedded. Sfruttando il vantaggio dell’indirizzamento dell’I2C è possibile inoltre collegare più dispositivi slave controllati da un unico master.
I2c è impiegata in una moltetudine di dispositivi hardware ed oramai è diventato uno standard de facto per quanto riguarda l’interfacciamento dei driver. La telecamera IP di Reolink e tutte le board di Novatek sono un buon esempio di questo. Seppur la tecnologia I2C richieda pochi fili per più dispositivi, presenta anche alcuni problemi che non bisogna trascurare durante la progettazione. Tra questi troviamo la velocità di scambio dati che è molto lenta perché per scambiare un byte di dati sono richiesti almeno 7 messaggi. I2C presenta una logica complessa da implementare per via della sua caratteristica di associare un indirizzo ad ogni dispositivo. Potrebbe non essere quindi la migliore scelta per dispositivi con risorse estremamente limitate.
UART
UART è il secondo protocollo di comunicazione che quest’articolo vuole approfondire. UART è l’acronimo di Universal Asynchronous Receiver-Transmitter, un protocollo di comunicazione seriale asincrona in cui il formato dei dati e le velocità di trasmissione sono configurabili. Invia i bit di dati uno per uno, dal meno significativo al più significativo, inquadrati dai bit di avvio e di arresto in modo che la tempistica precisa sia gestita dal canale di comunicazione.
Affinché UART funzioni, le impostazioni devono essere le stesse sia sul lato trasmittente che ricevente. È possibile configurare UART con:
- baud rate - impulsi per secondo, è il numero di cambi da 0 a 1 per secondo;
- bit di parità - utilizzato per verificare la presenza di errori;
- dimensione dei bit di dati;
- etichetta per riconoscere la fine dei dati - carattere che si aggiunge in fondo al frame di dati per identificare la fine dei dati da inviare;
- dati per il controllo del flusso - una serie di comandi per impostare UART;
La velocità che UART fornisce è molto simile alla velocità fornita da un’interfaccia I2C e funziona in modo molto similare all’interfaccia I2C. Il protocollo UART può operare in 3 diversi modi:
- simplex - i dati sono convogliati in un’unica direzione: dalla sorgente A a ricevitore B;
- half-duplex - i dati possono essere inviati sia da A che da B, però non possono essere inviati dati simultaneamente;
- full-duplex - i dati possono essere inviati sia da A che da B e possono essere inviati dati contemporaneamente;
A differenza del protocollo I2C, il protocollo UART non ha alcun clock di riferimento, non può quindi basarsi sul concetto di tempo per sapere quando iniziare a leggere i bit. Per questo, quando l’UART riceve un bit di avvio, inizierà a leggere i bit alla velocità definita da baud rate. Fondamentale quindi che ricevitore e sorgente adottino la stessa configurazione pena la perdita dei dati.
Metodi migliori
Non esiste un metodo assolutamente migliore per quanto riguarda la comunicazione tra scheda madre e dispositivi di Input/Output. Da caso a caso infatti il produttore può scegliere se ottenere più velocità, a costo delle risorse, o viceversa, risparmiare per avere una quantità minore di dati.
Ora che abbiamo approfondito tutte le sezioni per interfacciarsi con l’hardware e sapendo degli eventuali svantaggi di ogni tecnologia, possiamo passare ad analizzare un driver contenuto nella cartella lib. Appuntamento a mercoledì prossimo per analizzare meglio un driver che utilizza in modo molto approfondito il protocollo I2C.
Reolink Serie
- Parte 1 – Introduzione all'Analisi del Firmware di una Telecamera IP ReoLink
- Parte 2 – Avvio di un OS Embedded: la Fase di Booting e U-Boot
- Parte 3 – Esplorare Hardware di ReoLink RLC-810A
- Parte 4 – Approfondire UBI FileSystem nei Dispositivi Embedded
- Parte 5 – Esplorare il Sistema Operativo di Reolink RLC-810A
- Parte 6 – Tecniche per Impostare le Periferiche via DMA e PIO
- Parte 7 – Reverse Engineering del driver Omnivision OS12D40

