Monitorare la propria infrastruttura con Grafana, InfluxDB e CollectD
Pubblicato il – 8 minuti di lettura – 1539 parole
Per alcune aziende, le infrastrutture sono il cuore del loro business. In particolare, mi riferisco a quelle aziende che hanno la necessità di gestire dati e applicazioni che si trovano su più di un server.
Risulta quindi necessario monitorare i nodi dell’infrastruttura, specialmente se non si ha l’accesso in loco per poter intervenire su possibili problemi. Infatti, l’uso intensivo di alcune risorse possono essere indice di malfunzionamenti o indice di sovraffollamenti. Tuttavia, oltre al prevenire, il monitoraggio potrebbe essere utilizzato per valutare possibili implicazioni di un nuovo software in ambiente di produzione. Attualmente, in commercio, vi sono diverse soluzioni già “pronte per l’uso” per tenere traccia di tutte le risorse consumate. Tuttavia, troviamo quindi due problemi: il costo e la sicurezza.
Il primo a livello economico: i prezzi variano da 10 euro al mese fino a migliaia in base a quanti host devi monitorare. Quindi, immaginiamo che abbia 3 nodi da monitorare per un anno; anche fosse 10 euro al mese, spenderei circa 120 euro. Questo solo perché sono un privato: ho trovato prezzi enterprise che oscillavano tra i 10,000 e i 20,000 all’anno. Una spesa sostenibile per un’azienda grande, ma non per molte realtà locali.
Il secondo invece è più critico: tutti i dati dell’infrastruttura per poter essere visti ed analizzati devono passare da un’azienda terza. Come l’azienda riesce a catturare i dati per poi poterli mostrare al cliente? Molto semplice, l’azienda terza spesso raccoglie i dati tramite un custom agent da installare sul vostro nodo da monitorare: molto spesso, poco aggiornato e non sempre compatibile con tutti i sistemi operativi. Già in passato, diversi ricercatori di sicurezza avevano scoperto problemi importanti su “collector” proprietari. Vi fidereste? Io no.
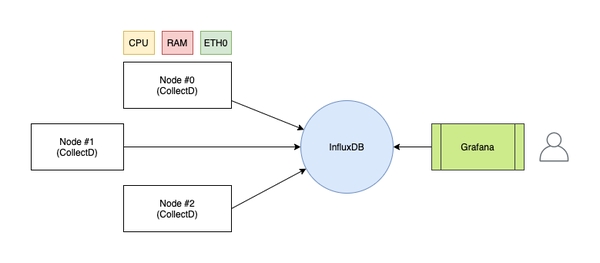
Mantenendo nodi sia per Tor che per alcune cryptocurrencies, ho preferito optare per un’alternativa senza costi, facile da configurare e open-source. Utilizzeremo la triade: Grafana, InfluxDB e CollectD.
Monitorare
Per poter analizzare ogni metrica della nostra infrastruttura è necessario utilizzare un programma in grado di catturare le statistiche sulle macchine che vogliamo monitorare. A tal proposito, CollectD viene in aiuto: si tratta di un daemon che raggruppa e colleziona (da qui il nome) tutti i parametri che possono essere memorizzati su disco o inviati in rete.
I dati verranno trasmessi a un’istanza di InfluxDB: un particolare database time-serie che associa ad ogni dato il tempo (codificato in UNIX timestamp) in cui il server ha ricevuto. Così facendo, i dati inviati da CollectD saranno già predisposti in maniera temporale, come una successione di eventi.
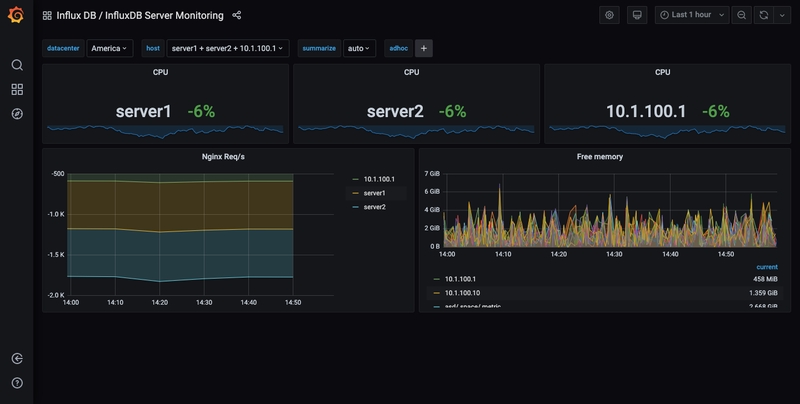
Infine, si utilizzerà Grafana che si collegherà ad InfluxDB in modo da creare dashboard appariscenti per visualizzare in maniera “più umana” i dati (e non diventando pazzi). Attraverso istogrammi e grafici di ogni tipo, sarà possibile osservare in tempo reale tutti i dati relativi a CPU, RAM e molto altro ancora.
InfluxDB
Partiamo da InfluxDB che costituisce il cuore pulsante del nostro “sistema” di monitoraggio. InfluxDB (inflàcs) è un database time-serie open-source sviluppato in linguaggio Go per poter archiviare i dati come una successione di eventi.
Ogni volta che viene aggiunto un dato, in realtà, viene collegato ad un timestamp UNIX di default. Questo consente un enorme flessibilità all’utilizzatore che non si deve più preoccupare di salvare anche la variabile “tempo”, talvolta macchinosa da configurare. Immaginiamo di avere diverse macchine dislocate su più continenti, come possiamo gestire il salvataggio del tempo? Utilizziamo il meridiano di Greenwich per tutti i dati? O impostiamo un fuso orario diverso per ogni nodo? Se i dati sono salvati su tempi diversi, come è possibile visualizzare i grafici? Tutto diventerebbe molto complicato.
InfluxDB ha il vantaggio di poter scrivere contemporaneamente su un certo database: è per questo che spesso si immagina InfluxDB come una linea temporale. La scrittura di un dato non inficia sulle prestazioni del database (come alcune volte avviene in MySQL): una scrittura è l’aggiunta di un certo evento alla linea temporale. Il nome del programma deriva proprio dalla concezione del tempo come un “flusso” infinito ed indefinito che scorre.
Installazione e configurazione
Un altro vantaggio di InflxuDB sta nella semplicità dell’installazione e nella corposa documentazione fornito dalla comunità che supporta ampiamente il progetto. Esso ha due tipi di interfaccie: via Command Line (potente e flessibile per gli sviluppatori, ma mal predisposta per vedere grosse quantità di dati) e un HTTP API che permette di una comunicazione diretta con il database.
InfluxDB è scaricabile oltre che dal sito ufficiale anche dal gestore di pacchetti della propria distrubuzione (nell’esempio si utilizza un sistema Debian). È consigliabile verificare il pacchetto tramite GPG prima dell’installazione, quindi importiamo le chiavi del pacchetto InfluxDB:
curl -sL https://repos.influxdata.com/influxdb.key | sudo apt-key add -
source /etc/os-release
echo "deb https://repos.influxdata.com/debian $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/influxdb.list
Infine aggiorniamo ed installiamo InfluxDB:
apt-get update
apt-get install influxdb
Per avviarlo, utilizziamo systemctl:
service start influxdb
Per assicurarsi che nessuno di malitenzionato entri, creiamo l’utente “amministratore”. InfluxDB utilizza un particolare linguaggio di interrogazione chiamato “InfluxQL”, molto simile a SQL, che permette di interagire con il database. Per creare una nuova entry, utilizziamo la query CREATE USER.
influx
Connected to http://localhost:8086
InfluxDB shell version: x.y.z
>
> CREATE USER admin WITH PASSWORD 'MYPASSISCOOL' WITH ALL PRIVILEGES
Dalla stessa interfaccia CLI, andiamo a creare il database “metrics” che verrà utilizzato come contenitore per le nostre metriche.
> CREATE DATABASE metrics
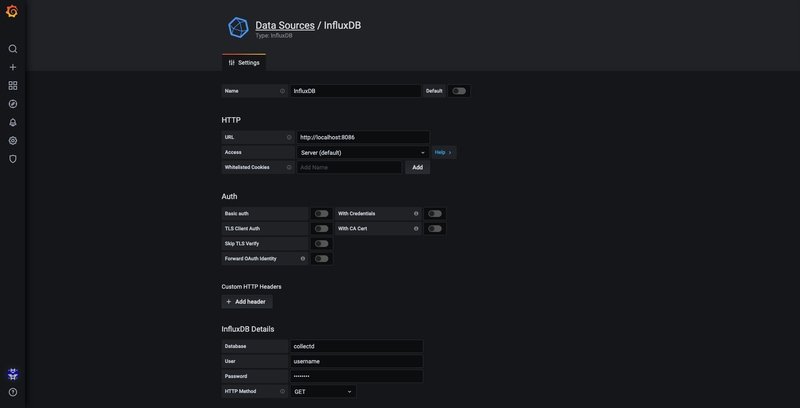
Successivamente, andiamo a modificare la configurazione di InfluxDB (/etc/influxdb/influxdb.conf) per avere l’interfaccia aperta sulla porta 24589 (UDP) con la connessione diretta al database nominato “metrics” in supporto a CollectD. È necessario inoltre scaricare e posizionare il file “types.db” in /usr/share/collectd/ (o in qualsiasi altra cartella) per definire i dati che CollectD manda in formato nativo.
nano /etc/influxdb/influxdb.conf
[Collectd]
enabled = true
bind-address = ":24589"
database = "metrics"
typesdb = "/usr/share/collectd/types.db"
Per ulteriori informazioni sul blocco “collectd” all’interno della configurazione, rimando alla documentazione.
CollectD

CollectD è un aggregatore di dati, responsabile, nella nostra infrastruttura di monitoraggio, della trasmissione dei dati a InfluxDB. Di default, CollectD cattura metriche su CPU, RAM, memoria (su disco), interfaccie di rete, processi e molto altro. Le potenzialità del programma sono infinite dato che può essere esteso con l’abilitazione di plugin già preinstallati o la creazione di nuovi.
Installare CollectD è molto semplice:
apt-get install collectd collectd-utils
In modo basilare, citiamo un esempio per illustrare il funzionamento di CollectD. Supponiamo di voler verificare quanti processi il mio nodo ha, CollectD non fa altro che effettuare un API call per ottenere il numero dei processi ogni unità di tempo (definita di default a 5000). I dati una volta catturati saranno inviati a InfluxDB tramite un modulo - da configurare - chiamato “Network”.
Apriamo il file /etc/collectd.conf con il nostro editor preferito e scorriamo fino a trovare la sezione Network: modifichiamo come scritto nel seguente snippet, avendo cura di specificare l’ip dove c’è l’interfaccia di InfluxDB (INFLUXDB_IP).
nano /etc/collectd.conf
...
<Plugin network>
<Server "INFLUXDB_IP" "24589">
</Server>
ReportStats true
</Plugin>
...
Il mio suggerimento è anche quello di modificare all’interno della configurazione l’hostname che viene inviato a InfluxDB (che nella nostra infrastruttura è un database “centralizzato” dato che risiede su un solo nodo). Così facendo, i dati non saranno ridondanti e non c’è alcun rischio che altri nodi sovrascrivano le informazioni.

Grafana

A graph is worth thousand of images
Ricordando la famosa “citazione”, osservare in diretta le metriche dell’infrastruttura attraverso grafici e tabelle è molto importante per poter agire in modo tempestivo. Per creare e configurare la dashboard mostrata all’inizio, utilizzeremo Grafana.
Grafana è uno strumento open-source compatibile con una vasta gamma di database (tra cui InfluxDB) che permette la visualizzazione delle metriche in grafici e consente di creare degli avvisi se un dato in particolare soddisfa una condizione. Ad esempio, se la CPU raggiunge picchi elevati, è possibile essere notificati su Slack, Mattermost, per email e molto altro ancora. Per esempio, io personalmente ho configurato un avviso ogni volta che qualcuno entra in SSH, così facendo posso monitorare attivamente chi “entra” nella mia infrastruttura.
Grafana non richiede particolari settaggi: ancora una volta, è InfluxDB a “scandire” la variabile del tempo. L’integrazione è estremamente semplice: incominciamo, scaricando il pacchetto dpkg dal sito ufficiale di Grafana (dipende dal OS che state usando):
wget https://dl.grafana.com/oss/release/grafana_7.0.3_amd64.deb
dpkg -i grafana_7.0.3_amd64.deb
Avviamolo attraverso systemctl:
systemctl start grafana-web
Successivamente, andiamo sulla pagina localhost:3000 attraverso il browser, ci si dovrebbe presentare un’interfaccia di login per Grafana. Di default, si deve utilizzare admin come username e admin come password (è consigliabile cambiare la password dopo il primo login).
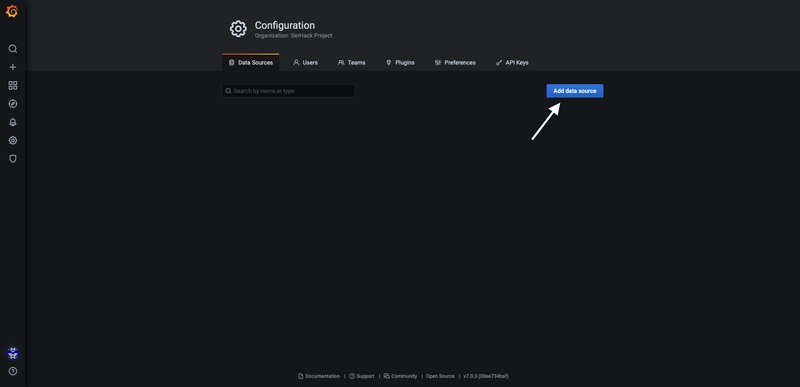
Andiamo su Sorgenti e aggiungiamo il nostro database di Influx
Lo schermo ora mostra un piccolo rettangolo verde proprio sotto la nuova dashboard. Passa il mouse su questo rettangolo e seleziona “Aggiungi pannello”, quindi “Grafico”:
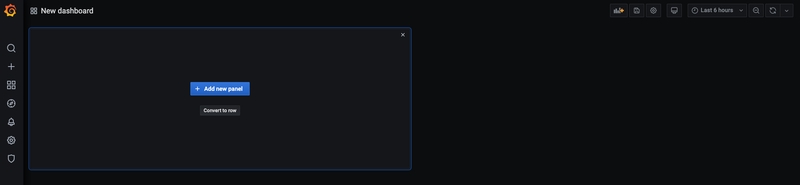
Grafana permette la scrittura di query intelligenti: non si deve per forza conoscere ogni campo del database, Grafana ce le propone attraverso una lista da cui possiamo scegliere il parametro da analizzare.
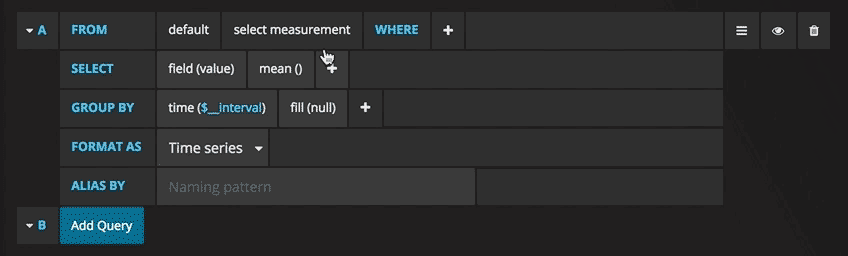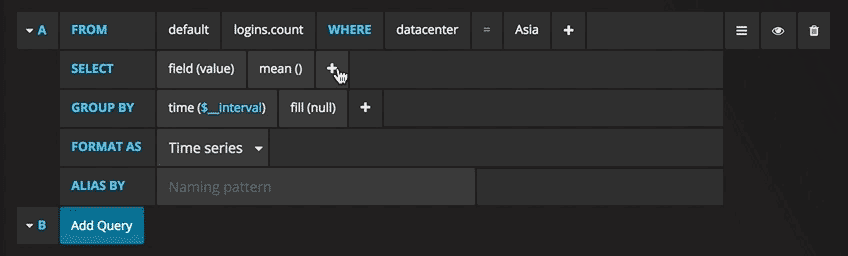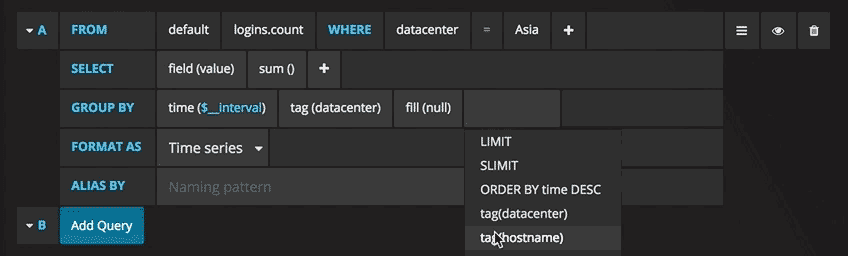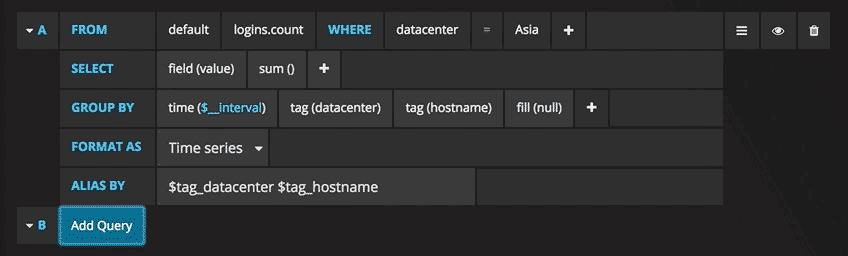
Scrivere le query non è mai stato così semplice: basta selezionare la misura che si vorrebbe tracciare e cliccare su Refresh. Consiglio inoltre di differenziare le metriche per hostname, così è più facile isolare eventuali problemi. Se cercate altre idee per creare dashboard, vi consiglio di visitare Grafana showcase per trarre ispirazione. Dal numero degli utenti SSH, al tenere traccia di ogni utente che visita un certo sito web: l’unico limite è la creatività.