6. Architettura standard di un decompilatore
La maggior parte dei decompilatori sono organizzati come un numero di moduli che estraggono vari tipi di informazioni dal file binario. Questa modularizzazione segue l’organizzazione tipica dei compilatori. In effetti, per la definizione di compilazione anche un decompilatore può essere visto come un compilatore. A tal proposito, si veda il dragon book per una trattazione molto più ampia sui compilatori e sulla progettazione di tali strumenti.
Lo scopo principale di avere la modularità è semplificare il porting del decompilatore su un processore diverso o testare nuovi algoritmi senza dover riscrivere l’intero codice ogni volta. Vuoi estendere un decompilatore includendo ARM? Puoi farlo senza problemi con i moduli. Trovi innumerevoli problemi su una certa caratteristica? Puoi isolarne i dettagli senza dover incolpare l’intera applicazione di un comportamento imprevisto.
La figura seguente illustra i vari moduli e la loro relazione:
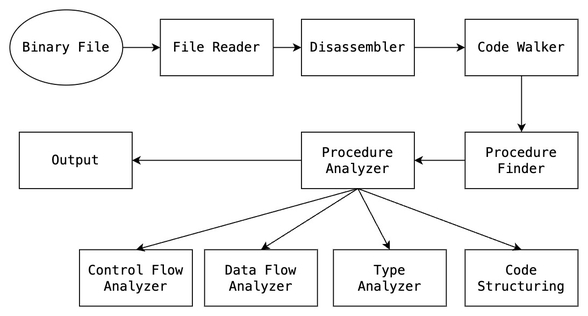
A prima vista si potrebbe supporre che il file di input venga elaborato in sequenza da ciascun modulo finché i dati trasformati non raggiungono il modulo di output. Vedremo nella sezione avanzata che non è possibile eseguire la decompilazione avanzata in un singolo passaggio sul programma di input. L’uso di passaggi multipli può rendere alcune analisi più complicate dal punto di vista della complessità, ma darà risultati molto migliori.
Di seguito andremo ad illustrare i principali step che un decompilatore dovrebbe fare per effettuare un analisi completa ed ottenere un buon risultato di decompilazione. Tali passi sono effettuati dai principali decompilatori che troviamo in commercio, come IDA e Ghidra, pertanto invitiamo per chi fosse più curioso a consultare la documentazione dei due programmi per capirne di più.
File Reader: parsing delle strutture dati dell’eseguibile
Come vedremo nella sezione successiva, il primo step per il decompilatore consiste nell’effettuare il parsing delle strutture binarie che compongono l’eseguibile. Sappiamo infatti che qualsiasi programma include due principali categorie di informazioni: istruzioni e dati. Esistono varianti a non finire di formati file esegubili, ma ciò che osserviamo tra questi è la memorizzazione di queste informazioni.
Abitualmente un file binario, sia esso PE o ELF o MachO, consta sempre di:
- una intestazione che comprende una serie di informazioni come il magic number, il target del binario, alcune informazioni sul tipo di file (se è rilocabile o meno, se presenta alcune caratteristiche). Le informazioni realmente importanti per il decompilatore sono: la CPU per cui il binario può essere eseguito e l’offset all’main entry del programma.
- le intestazioni delle strutture dati, come tabelle, alberi e molto altro;
- sezioni che comprendono generalmente solo un certo tipo di informazione (ad esempio
.textper le istruzioni,.dataper i dati). Considera che non c’è un obbligo per cui le istruzioni sono solo in una certa sezione, così come non è vero che i dati sono contenuti solo all’interno della sezione.data.
Disassembler: distinguere tra dati e istruzioni
Una volta individuata la sezione che contiene le istruzioni e il punto di ingresso, è ora di effettuare il disassemblaggio. Il disassemblatore non fa altro che ricevere in input una sequenza di byte e produrre la versione “leggibile” dell’assembly. Il disassemblatore può anche restituire una serie di strutture dati che possono essere utilizzate per analizzare ulteriormente le istruzioni senza avere il problema del tokenining.
Il disassemblaggio è dipendente dall’architettura target del file eseguibile. Quindi in base al tipo di CPU (x86 o ARM, ad esempio), il disassemblatore deve effettuare una scelta rispetto al tipo di istruzione che deve decodificare.
In realtà, esistono due principali tecniche per disassemblare un file oggetto:
il primo prevede che tutte le istruzioni contenute all’interno della sezione “.text” siano considerate sequenziali. Non è prevista la possibilità di avere dei dati all’interno della sezione istruzioni, quindi il disassembler prevede di prendere l’intero buffer dei dati della sezione .text e di consumarlo in maniera lineare/sequenziale. Questo assicura di finire in un tempo certo dato che la scansione lineare di un buffer, tuttavia è un approccio rischioso dal momento che il compilatore può inserire diverse informazioni all’interno della sezione .text. L’operazione dipende solamente dal tempo di scansione (N) e il tempo di decoding dell’istruzioni (variabile, però tempo costante).
il secondo approccio prevede invece una scansione “ricorsiva” delle istruzioni. La “scoperta” delle istruzioni è basata sul punto di partenza (entry point) del main di un programma. Mano a mano che il disassemblatore procede a decodificare le istruzioni cerca anche altre sezioni non ancora esplorate del binario. Ad esempio se un’istruzione è una call ad un certo offset/indirizzo non ancora esplorato, il disassemblatore dovrebbe essere in grado di seguire quell’indirizzo e partire da quella istruzioni per le successive. Abitualmente è l’approccio più utilizzato da parte dei decompilatori e disassemblatori commerciali perché consente di avere una visione molto più dettagliata delle istruzioni. Questo non assicura di finire in un tempo certo (non è neanche certo che il disassemblatore possa finire il decoding delle istruzioni) ipotizzando una area di memoria infinita. Se le istruzioni venissero generate a tempo d’esecuzione da zero, il disassemblatore potrebbe ricadere in un ciclo infinito.
Il secondo approccio è quello definitivo e che dovremo attualmente mirare per costruire un serio decompilatore in grado di esplorare in maniera esaustiva il programma. Nota che la maggior parte dei problemi menzionati in questo corso non hanno una soluzione algoritmica; possono essere applicate delle euristiche per tentare di arrivare ad una soluzione approssimata.
Code Walker
Questo modulo prevede di analizzare le istruzioni e verificare che ogni indirizzo sia stato disassemblato. Nota che il code walker è intrinsicamente legato al disassemblatore. Qui è importante separare molto nettamente il codice (istruzioni) dai dati. È per questo che il disassemblatore dovrebbe notificare il code walker di ogni istruzione “invalida”.
Si presuppone infatti che i binari eseguibili non contengano istruzioni non valide. Le istruzioni non valide generano un interrupt che il sistema operativo gestisce in diversi modi. La maggior parte delle volte, istruzioni errate possono portare il sistema operativo a terminare il processo (tramite il segnale SIGILL). Istruzioni errate possono essere considerate come una separazione tra istruzione e dato.
Procedure Finder
Il modulo ha come obiettivo la ricerca di tutte le procedure: funzioni e sottofunzioni. In modo molto riassuntivo, il modulo scansiona tutte le istruzioni alla ricerca di un jump e identifica tutto quello che c’è all’indirizzo del jump come una funzione. Come vedremo successivamente, bisogna stare attenti dal momento che non tutti i jump identificano in modo netto una funzione.
Procedure Analyzer
Uno degli ultimi step dei decompilatori riguarda l’applicazione delle euristiche per cercare di rappresentare più informazioni ad alto livello possibile. Nelle prossime pagine troveremo gran parte delle euristiche spiegate con gli algoritmi in modo da implementarli in un decompilatore didattico.
