Phishing: Persuading People through a Voice Synthesized by AI - Part 1
Published at – 8 min read – 1701 words

I get between 10 to 20 emails per day and, usually, more than half of them are phishing attempts. Phishing attempts are a type of email scam that typically aims to obtain personal data of the victim, including username and password for email accounts and popular services (Gmail, Hotmail, mail.ru, Twitter, Amazon, etc.), through pages forged ad hoc to simulate login sections.
“Your account has been blocked for security checks.”; “The package is about to be delivered, but…”; “Your domain has expired.” These are just a few examples of the contents/messages that the user receives in order to catch their attention and push them to click on the “owl” link, which is often disguised in such a way so as to appear legitimate. There are various techniques that allow attackers to succeed, such as email messages without grammatical errors, domains that look like the originals but differ by one or more letters, and many other deceptive tricks.
My analysis has focused on a more targeted approach to psychology. Is it possible to persuade a person to enter their personal data through a voice generated by artificial intelligence?
Social Engineering and Phishing
Social engineering is using manipulation, influence and deception to get a person, a trusted insider within an organization, to comply with a request, and the request is usually to release information or to perform some sort of action item that benefits that attacker. ~ Kevin Mitnick
Social engineering is defined as “the art” of cunningly obtaining information that should not be disclosed. There are various methods for obtaining data of interest, including phishing, but also pretexting, baiting, and quid pro quo attacks. The ultimate goal of the attacker is to obtain credentials or provoke an action that is beneficial to the attack.
In this article, I will focus on spear phishing, which is a targeted attack that attempts to extract any sensitive information by exploiting the naivety of the user to whom it is directed. Initially, we use email spoofing as “bait” to attract attention and get the user to enter their credentials on a page created by the attacker.
The phenomenon of spear phishing began in the mid-1990s when a 17 year old known as “Da Chronic” released the tool “AOHell” that enabled nefarious actors to generate fake pages to obtain passwords and credit card information from AOL social network users. Since then, the number of phishing messages and emails has increased exponentially and the techniques have become more refined. To date, every year there are more than 200 million attempted attacks, not counting the hundreds of thousands of spam emails that hopefully end up in your spam folder. During the still ongoing period of COVID-19, the APWG (Anti-Phishing Working Group) has noticed an increase in attacks mainly against health facilities and state infrastructures.
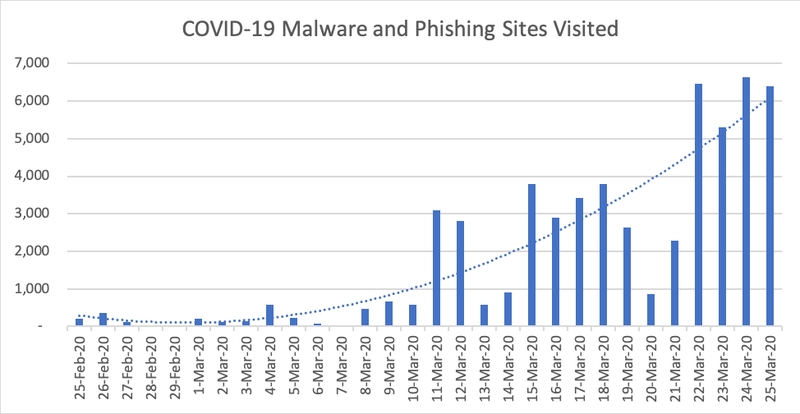
The following graph has been taken from Menlo Security
Psychology: Techniques of Persuasion and Prosody
There are various techniques to persuade the user into giving up their credentials. Simply put, you clone the page of interest to mirror the likeness of the original page. Here, the hope is that the user who is being exploited may not be as diligent and thorough and, likely, will not check the authenticity of the cloned page and simply enter their credentials without giving it a second thought.
Can you take the complexity of a phishing attack to another level? Very often, they are just login pages. What if an attack is more elaborate? I was particularly interested in one technique ― persuasion by voice. Scientific research has shown that people are more predisposed to perform some action if commanded by a human voice. Is it possible, however, to have the same (or better) result with a voice “synthesized by artificial intelligence”? What if such an approach was applied to a login page?
As mentioned above, will there is some scientific research showing that people are more predisposed to perform some action if commanded by a human voice, little is known about how much more convincing an artificially synthesized voice actually is than a human voice.
A cross-study exploratory analysis and replication experiment reveal that communicators tend to speak louder and vary their volume during paralinguistic persuasion attempts, both of which signal confidence and, in turn, facilitate persuasion. “How the Voice persuades”
Artificially synthesized language does not have all the characteristics of the human voice to express and transmit emotions. However, the Web Speech API has some modifiable elements of prosody. Prosody includes all “secondary” aspects of language such as the tone of voice (pitch), length of sounds (speed), volume (volume), and sound quality.
The prosody provides additional information about the attitude and meaning of a sentence. Greeting and asking for information, depending on the tone, can yield different results.
Web Speech API: Speech Synthesis
In 2012, a group of the W3C community meet and developed a new standard called [“Web Speech API”] to provide developers with an interface for “speech-to-text” and “text-to-speech”. It allows the application to both understand text from a user’s speech and to transform text into spoken speech through a voice synthesized by artificial intelligence. Starting with Chrome 33, an experimental API was released and officially introduced in 2014.
SpeechSynthesisUtterance represents a vocal request.

rate: sets the speed, accepts values between [0 and 10].pitch: sets the tone, accepts values between [0 - 2].volume: sets the volume, accepts values between [0 - 1].lang: sets the language (BCP language tag 47, like en-US or en-IT)text: sets the text, can contain maximum 32767 charactersvoice: set the entry among the 52 available (to get them, usewindow.speechSynthesis.getVoices();)
var msg = new SpeechSynthesisUtterance();
var voices = window.speechSynthesis.getVoices();
msg.voice = voices[0];
msg.lang = 'it-IT';
msg.pitch = 1.0;
msg.text = 'Mi piace la pizza';
speechSynthesis.speak(msg);
To execute the request, you must call the “speak” function of the “speechSynthesis” method: speechSynthesis.speak(obj). As specified in Chromium source code, the attributes volume, rate, pitch accept float values. Changes of values like volume during a voice request will be applied to the next call of speechSynthesis.speak(obj).
Tips and Tricks
Not all entries are present in the browser. Some are only available online, but if not specified, the entry will use the accent of the language set in the browser. You can also change the voice.localService parameter to set whether or not the synthesized voice is provided online (to save bandwidth ndr). Remember that the language offset from the AI synthesized language can generate suspicions (red flags) not only because it has a different accent, but because the numbers and percentages are read according to the AI language. For example, if you use a preset entry for it-IT with lang en-US, the following string 2% will be due percento and not two percent.
When the API was implemented in 2014 with Chrome, there was a growing phenomenon of API abuse in mobile and desktop advertising. For this reason, Chrome currently requires iteration (one touch) by the user in order to request the API; however, Safari and Firefox do not impose this limit. A trivial modal for “Accept Cookies” might work.
The more targeted the phishing campaign is, the more successful it will be. For this reason, it was preferred to use the user’s name to direct the user several times. If the tab became inactive, the browser will call the user.
// Since the card can be "active" or "closed", I increase the close variable by 1 each time there is a visibility change event. When the counter is even, then the card is closed, so I call the user.
var close = 0;
document.addEventListener('visibilitychange', function(){
close++;
if(close % 2) remind_user();
});
To avoid redundant code, you create a speak() function that calls the SpeechSynthesis API.
function speak(message, speed, pitch){
var speech = new SpeechSynthesisUtterance();
var voices = window.speechSynthesis.getVoices();
// The voice is linked to English
speech.voice = voices[8];
// Suppose we always have the same user
speech.lang = 'en-US';
speech.rate = speed;
speech.pitch = pitch;
speech.text = message;
}
An exercise left to the reader is to develop through backend a custom page given only the name of the user to be tagged (the language is often given on the User-Agent, even if sometimes it can be misleading).
Moreover, in order not to overlap the requests, we use the onspeak events in conjunction with the clicks made by the user. In fact, we pause all entries in case the user starts writing his credentials (the input element changes state in focus).
One of the key points is the content of the entry. I opted for a more “direct” and categorical approach using imperative verbal elements. Instead of a cordial sentence, such as “please [verb]”, I chose to use “[verb]” to induce the action immediately as if it were a “Call To Action”. Example: “Write your username and password to continue”.
Hypothesis
I have not found much research on this topic and it appears that little is actually known (yet) about a possible link between elements of prosody and the resulting action. This article could be a good starting point to conduct more “academic” scientific research.
Although limited, let’s try to hypothesize some scenarios in front of which users may find themselves. As we can observe, voice persuasion is only an additional element to a phishing campaign. The graphical elements and the email built ad-hoc must be there in order to have a more effective phishing campaign.
Since Web Speech is not widely used, let alone on login pages, voice in many cases could be off-putting to a user. In this case, it is assumed that the user suspects a phishing attempt and leaves the page.
A more interesting case concerns the use of voice assistants. If you implemented a web page that played a voice assistant, people would expect a voice. The voice element no longer plays as a “surprise factor”; moreover, the AI robotic voice implemented on major Chromium-based browsers is very similar to the voice of the Google voice assistant.
The following assumptions were tested on a limited sample. If you would like to participate and further this research, so that you can help prove or disprove this theory, here is my email. Feel free to write me!

